
AI and information retrieval
AI tools can speed up and simplify scientific information retrieval. At the same time, it is important to be aware of the risks. On this page you will learn more about AI search tools and what you should consider when using them.
Artificial intelligence (AI) is a broad term, and some technologies have been in use for a long time, such as relevance ranking and recommendations for similar content. In the most recent years, generative AI and natural language processing have become widely available and used.
Generative AI
Generative AI means that AI is used to generate digital content. The digital content can be text, images, music or some other material.
Generative AI is to a great extent based on probability. If a text starts like this, how would it most likely continue? Which words and sentences tend to occur together? Based on this, a unique text is generated. Since it contains commonly occurring combinations of words and sentences, the text will appear plausible and credible. Factual information will often be correct, but can also be completely wrong. This is known as “AI hallucination.”
Generative AI usually relies on large language models that can process natural language. They are trained using large amounts of data. The data used will greatly influence how the model functions. The data is often limited in time, and information about recent events and new research may be missing. The data can also be biased in various ways. Most large language models do not clearly state what data was used for training, which is a disadvantage in academic contexts where transparency is important.
AI tools that rely entirely on generative AI cannot provide sources for the information. The AI tool has not searched for information but only generated a text. Sometimes the AI tool can provide references, but often they are fictitious references that do not exist in reality.
Tools that are entirely based on generative AI cannot provide sources for the information. The AI tool has not retrieved information but only generated a text. If a tool entiely base on generative AI tool provides references, they may be fabricated and not exist in reality. In academic work, citing and checking source is important. It is essential to know where the information originally comes from and to be able to go back and review the sources. Without cited sources, this is not possible, and therefore, purely generative AI is not suitable for scientific information retrieval.
Many of the chatbots that were initially entirely based on generative AI now perform searches, usually on the Internet.This applies, for example, to Bing, Bard, and certain versions of ChatGPT. This development means that chatbots and internet searches using a search engine have become more similar. Both can be good ways to get started and gain an initial overview of a topic. It is a good idea to check the sources of a claim and assess how reliable the information appears to be.
AI tools for searching
A range of AI-based search tools has been developed. Many are based on Retrieval-Augmented Generation (RAG). RAG means that a search in an external source is combined with a language model. The search can be conducted on the Internet or in databases that, for example, may contain scientific publications. The search is usually a form of semantic search. Semantic means similarity in meaning or content, as opposed to similarity between characters, words, and phrases, which traditional (lexical) search relies on.
Semantic search in RAG is, in most cases, based on vector embeddings. The documents in the database are represented by vector embeddings—series of numbers.

When you perform a search, your query or prompt is also tranformed into a vector embedding. A comparison is made between the vector embedding representing the query and the vector embeddings in the database. The search results present the publications that most closely resemble the query or prompt. The language model and semantic search are often combined with other methods for searching and sorting information, such as keyword search, relevance ranking algorithms, and citation analysis.

The number of sources presented in the results is often quite small in RAG tools, and the result contains the same number of sources regardless of the prompt used. Searching in a RAG tool means ranking sources based on their degree of similarity, not retrieving sources that exactly match a search query.
In RAG-based search tools, the risk of fabricated references is eliminated. The references presented will exist. However, hallucinations in generated texts can still occur. It is also not guaranteed that information claimed to derive from a particular source is actually found there.
There are several RAG-based tools focused on scientific literature. Often, the exact data sources they use are not disclosed, but Semantic Scholar and OpenAlex are commonly used. These tools generally have access to the full text of some scientific articles, but not all. For articles with restricted access, the tools’ analysis of the sources will be based on the title and abstract. As for books—especially printed ones—they are rarely included in the data sources used.
Possibilities
RAG can be a valuable complement to lexical searching in traditional databases. It is easier to formulate a question in natural language than to construct an effective search using keywords and Boolean operators. Semantic search can help find sources that might otherwise be missed. The summaries generated can assist in more quickly identifying relevant sources. However, keep in mind that the summaries are not always accurate—read the original sources if you intend to use them in your own work.
In most RAG-based tools, you can formulate your search query or prompt using natural language. It is usually best to focus on describing the topic and avoid “prompt engineering” techniques used in chatbots. Phrases about how the answer should be structured, what types of sources to select, and other instructions not related to the topic itself may conflict with the RAG tool’s functionality and reduce the quality of the results.
Risks
A disadvantage of RAG-based tools is that the process of searching and selecting sources is not transparent. It is not possible to understand why certain sources are presented, nor how the ranking is determined.
Reproducibility is also lacking. Reproducibility means that someone else should be able to repeat, for example, a scientific experiment and obtain the same result. In terms of search, the same query performed by different people should yield the same results, as should the same query performed at different times. Due to the nature of generative AI, each generated text is intended to be unique. Even the sources retrieved may vary, meaning the same query repeated at different times or by different users may often yield different results. This makes it impossible to conduct systematic searches using these tools.
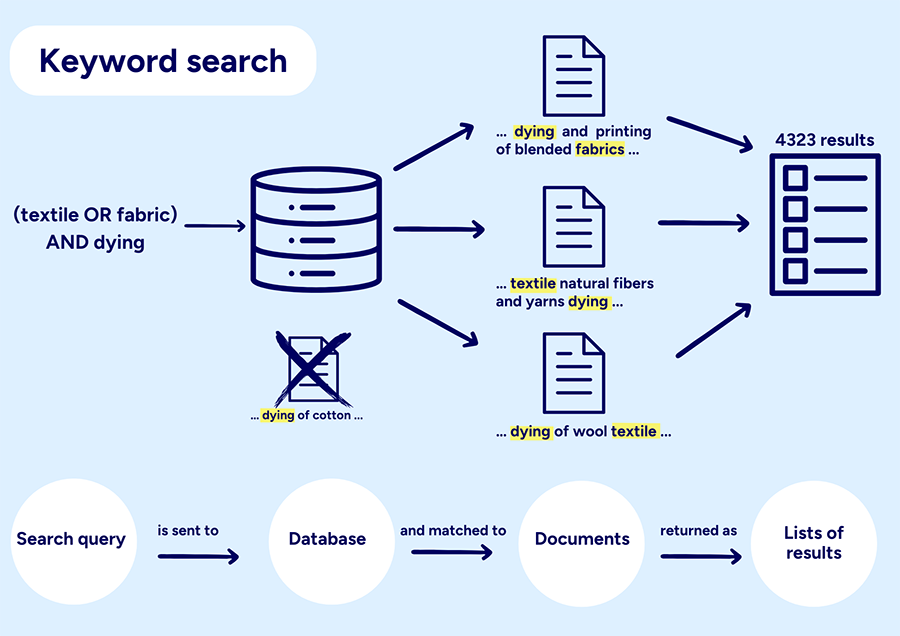
Keyword searches in a traditional database often provide an overview of the research on a particular topic. The number of hits gives an indication of how much the topic has been studied, and by reviewing the list of results, one can get a sense of common themes. When searching in a RAG-based tool, this overview is usually not provided. You receive the same number of results regardless of how much or how little research exists in the area you are asking about.
Terms of Use and Copyright
Many AI tools save the input you provide and use it in various ways, including as training data. Read the terms of use for each service to learn more, and be cautious if, for example, you input someone else’s material or sensitive information.
Copyright only applies to material created by human beings. AI-generated images and text are therefore not covered. No one holds copyright to AI-produced material. However, there may be restrictions on how the material can be used. These restrictions can be found in the terms of use you accepted when you created an account for the service.
Cheating and Plagiarism
Before using AI tools in your studies, you need to check what guidelines apply to the specific course. In general, you should never submit work as your own if you have not substantially completed it yourself. For the sake of transparency, it may be recommended to state which tools you used, and how. KTH's pages on cheating and plagiarism contain more information.
AI tools as a reference
Practice varies as to whether AI tools should be cited as references. They are not sources in the traditional sense and according to some recommendations they should rather be mentioned as tools used. If you need to reference AI tools, you can sometimes find examples of how to do so in a guide to the referencing style you are using.
