Projects during M.Sc.
Using GPU-aware message passing to accelerate high-fidelity fluid simulations (thesis 2022)
Motivated by the end of Moore’s law, graphics processing units (GPUs) are replacing general-purpose processors as the main source of computational power in emerging supercomputing architectures. A challenge in systems with GPU accelerators is the cost of transferring data between the host memory and the GPU device memory. On supercomputers, the standard for communication between compute nodes is called Message Passing Interface (MPI). Recently, many MPI implementations support using GPU device memory directly as communication buffers, known as GPU-aware MPI.
One of the most computationally demanding applications on supercomputers is high-fidelity simulations of turbulent fluid flow. Improved performance in high-fidelity fluid simulations can enable cases that are intractable today, such as a complete aircraft in flight.
In this thesis, we compare the MPI performance with host memory and GPU device memory, and demonstrate how GPU-aware MPI can be used to accelerate high-fidelity incompressible fluid simulations in the spectral element code Neko. On a test system with NVIDIA A100 GPUs, we find that MPI performance is similar using host memory and device memory, except for intra-node messages in the range of 1-64 KB which is significantly slower using device memory, and above 1 MB which is faster using device memory. We also find that the performance of high-fidelity simulations in Neko can be improved by up to 2.59 times by using GPU-aware MPI in the gather–scatter operation, which avoids several transfers between host and device memory.
Report | Presentation | Code
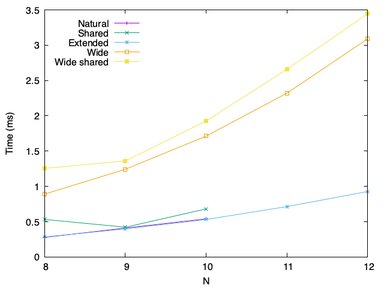
A GPU-accelerated Jacobi preconditioner for high-order fluid simulations (2022)
Next-generation scientific software must take advantage of acceleration to exploit emerging heterogeneous computing architectures. Neko is a new computational fluid dynamics code in development at KTH. The contributions of this work is to implement a GPU-accelerated Jacobi preconditioner in Neko to decrease the time to solve the pressure equation, and to compare the performance of different potential implementations on a NVIDIA A100 GPU. We find that a natural kernel design without use of shared memory performs the best. We conclude that on this device, automatic caching performs better than explicit use of shared memory, and that batching multiple computations in a single thread is not beneficial. Additionally, there is no apparent cache penalty for not matching execution blocks to geometric elements, allowing kernels to easily support arbitrary polynomial degrees.
Report | Code
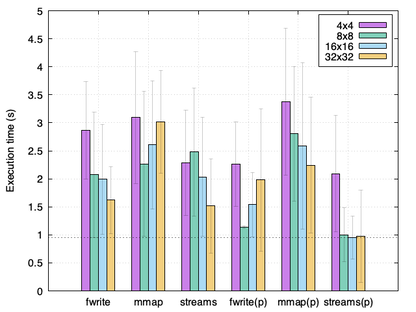
Analysis of IO techniques in a simple GPU ray tracer (2022)
Implementation of various IO techniques in a GPU ray tracer using CUDA. Performance evaluation on K240 and K80 GPU nodes at PDC. Results show that at large resolutions memory mapping has a big overhead cost, and that use of pinned memory is advantageous on the NVIDIA K240, while it is performance neutral on the NVIDIA K80.
Report | Code
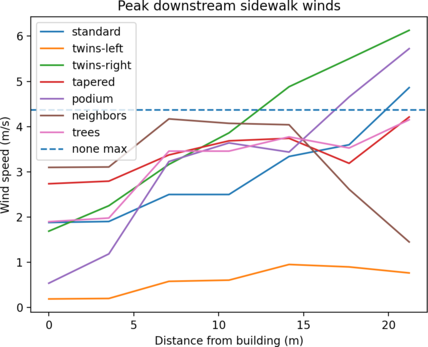
Comparing strategies for pedestrian wind comfort and safety around high-rise buildings (2021)
High-rise buildings may have an adverse effect on the pedestrian environment by causing strong winds at ground level. We investigate what the most effective building design to ensure pedestrian wind comfort and safety is. Different scenarios are compared using a Direct Finite Element Simulation (DFS) method. The mean and max wind speeds at pedestrian height is measured as well as the wind induced drag on the building. The scenario with smaller neighboring buildings stood out by reducing both wind speeds and drag, though the method needs improvement to draw strong conclusions.
Report | Presentation
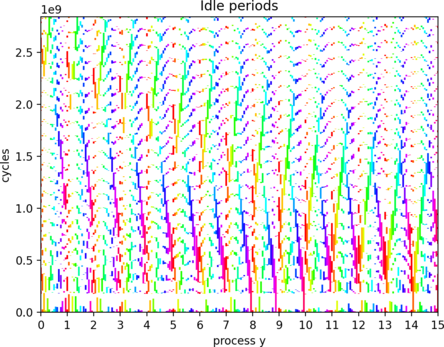
Idle period propagation in finite difference solver using MPI (2021)
Implementation of a solver for the 2D heat diffusion equation using the finite difference method with MPI paralellization. Visualization and analysis of the propagation of idle periods between MPI ranks. Visualization of experimental data shows that long idle periods propagate like a wave in the MPI grid.
3D Visualization | Presentation | Code